-
Normalized Rarity Score Formula:
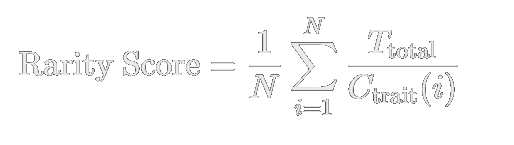
N = Total number of traits in the NFT (the number of distinct traits the NFT has).
Ttotal = Total number of NFTs in the collection (the total number of JSON files).
Ctrait(i) = Count of the specific trait 𝑖 across all NFTs in the collection (how many times trait 𝑖 appears).Nochillio #314
Score 15.5
Rank 699
View on:


Wallet holds: 314
-
Sourcecode for rarity.py
import os import json from collections import defaultdict # Path to the folder containing JSON files folder_path = "/path/to/json/files" def calculate_normalized_rarity_score(traits, total_nfts, trait_counts): """ Calculate the normalized rarity score for an NFT based on its traits. """ if not traits: return 0 # Handle edge case for NFTs with no traits return sum(total_nfts / trait_counts.get(trait, 1) for trait in traits) / len(traits) def process_json_files(folder_path): """ Process all JSON files in the given folder and calculate normalized rarity scores and ranks. """ # Count occurrences of each trait trait_counts = defaultdict(int) all_files = [f for f in os.listdir(folder_path) if f.endswith('.json')] # Sort files numerically by their names (e.g., 1.json, 2.json, ...) all_files.sort(key=lambda x: int(x.split('.')[0])) # First pass: Count traits across all JSON files for file_name in all_files: with open(os.path.join(folder_path, file_name), 'r') as file: data = json.load(file) for attribute in data.get("attributes", []): trait_key = (attribute["trait_type"], attribute["value"]) trait_counts[trait_key] += 1 # Total number of NFTs total_nfts = len(all_files) # Second pass: Calculate rarity score for each file rarity_scores = {} for file_name in all_files: with open(os.path.join(folder_path, file_name), 'r') as file: data = json.load(file) traits = [(attr["trait_type"], attr["value"]) for attr in data.get("attributes", [])] rarity_score = calculate_normalized_rarity_score(traits, total_nfts, trait_counts) rarity_scores[file_name] = rarity_score # Rank NFTs by rarity score (higher score = more rare) sorted_rarity = sorted(rarity_scores.items(), key=lambda x: x[1], reverse=True) rarity_ranks = {file: rank + 1 for rank, (file, _) in enumerate(sorted_rarity)} # Combine rarity score and rank into one dictionary rarity_data = {file: {"score": rarity_scores[file], "rank": rarity_ranks[file]} for file in all_files} return rarity_data # Run the script if __name__ == "__main__": rarity_data = process_json_files(folder_path) # Output rarity score and rank sorted by file name for file_name in sorted(rarity_data.keys(), key=lambda x: int(x.split('.')[0])): data = rarity_data[file_name] print(f"{file_name} - rarity score: {data['score']:.2f}, rarity rank: {data['rank']}") import csv # Save to CSV sorted by file name output_file = "rarity_data_sorted.csv" with open(output_file, "w", newline="") as csvfile: fieldnames = ["name", "rarity_score", "rarity_rank"] writer = csv.DictWriter(csvfile, fieldnames=fieldnames) writer.writeheader() for file_name in sorted(rarity_data.keys(), key=lambda x: int(x.split('.')[0])): data = rarity_data[file_name] writer.writerow({"name": os.path.splitext(file_name)[0], "rarity_score": round(data["score"], 2), "rarity_rank": data["rank"]}) print(f"Rarity data saved to {output_file}")
